nanochat学习-模型架构
从这里开始就是正式的代码学习了,首先开始的是gpt.py,也就是模型架构,karpathy在架构中添加了许多现代transformer的优化和改进,从而能够让训练的成本相对于gpt2大大降低,其中的改进和变化也能让我们看到从2019年到如今的科研界的种种进步(同时也增加了学习的内容和难度)
目录
背景知识
当你作为一个小白直接来看这个代码,当然会遇到各种各样的问题,而其中最大的问题就是学习当前知识的前置知识不够,我自己也感觉这是我学习过程中的一个非常痛苦的点。因为前置知识的不足,我们看到一个东西的时候会遇到大量的看起显然但是自己却非常无知的内容,这个时候就非常令人沮丧,进而导致学习动力的丧失,然后学习资料就这么开始在收藏夹吃灰了。。。当然了,当我们掌握了所有的前置知识的时候也就意味着我们学习的过程也就完成的差不太多了,剩下的部分我们只需要将各个部分进行相互联系即可。
所以,在正式的学习代码之前,我们需要大量的恶补前置知识
关于python
代码中用到的库:
dataclasses:dataclasses.dataclass用于创建数据类,简化配置类的定义,@dataclass装饰器让这个类自动生成__init__等方法,从而让GPTConfig这个类存储GPT模型的所有配置参数(简单理解就是能够更简单的来定义一个用来管理数据的类)torch: PyTorch深度学习框架的核心库,torch.nn就是其中的神经网络模块
关于torch
PyTorch大家肯定都知道,这里就来讲解一下有关torch.nn和torch.nn.functional的部分
torch.nn就是神经网络的层的类,一个具体的深度学习神经网络模型有很多层,每一层都会有一个状态(维护层中存储的模型参数)。我们需要通过这个类来进行实例化,例如nn.Linear(config.n_embd, 4 * config.n_embd, bias=False)就是创建一个线性层的实例,输入的纬度是config.n_embd,输出的纬度是4 * config.n_embd,也就是对输入进行4倍的升纬,然后没有添加bias,即经过这个层就是输入一个n * 1向量之后对这个向量左乘以一个4n * n的权重矩阵,图中箭头上面的权重也就是矩阵当中的一个参数,即y = W * x(注意这个图有一点不太准确的地方是中间不需要画那个蓝色的W块,箭头本身其实就是权重矩阵W,很多论文中也会用箭头的颜色深浅来表示参数的大小不同),如果是有bias的话就是再加上一个b向量,这个也是可学习的参数。
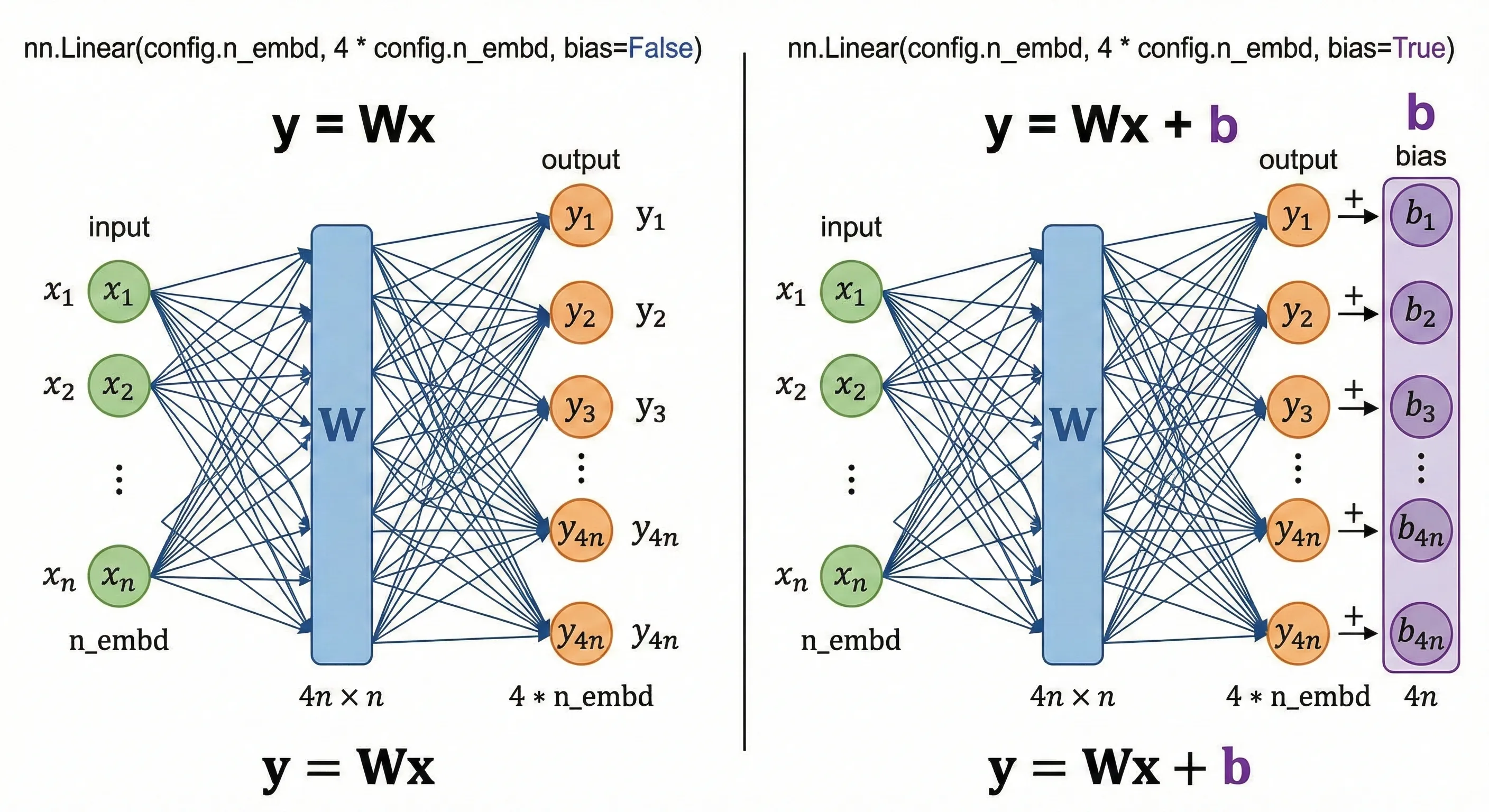 线性层其实就是整个神经网络的基础,乘以一个W矩阵就是对输入向量做一次线性变化,如果加上偏置的话也就是给线性变换之后的向量加上一个偏移向量
线性层其实就是整个神经网络的基础,乘以一个W矩阵就是对输入向量做一次线性变化,如果加上偏置的话也就是给线性变换之后的向量加上一个偏移向量
而torch.nn.functional就是一系列的函数工具,用来进行数学计算的,通过向其输入内容我们可以得到结果
关于注意力机制、多头注意力机制、前馈神经网络、残差连接的更加具体的理解可以看我的这篇博客,感觉还是讲解的比较详细和清楚
Attention
简单理解attention机制就是让某个token能够关注到来自序列中其他token的信息然后更新自己,起到了一个融合信息的作用。那么其计算公式我们就可以想到,对于序列中的某个token来说,它对于序列中的每一个其他的token所需要的关注程度是不同的,那么我们就需要为每一个token计算出来一个注意力分数,然后让序列中所有token对应的注意力分数的和为1,那么每个token的注意力分数就是其注意力权重,我们再做来自每个token信息的加权和就可以得到当前token需要关注的来自整个序列的信息
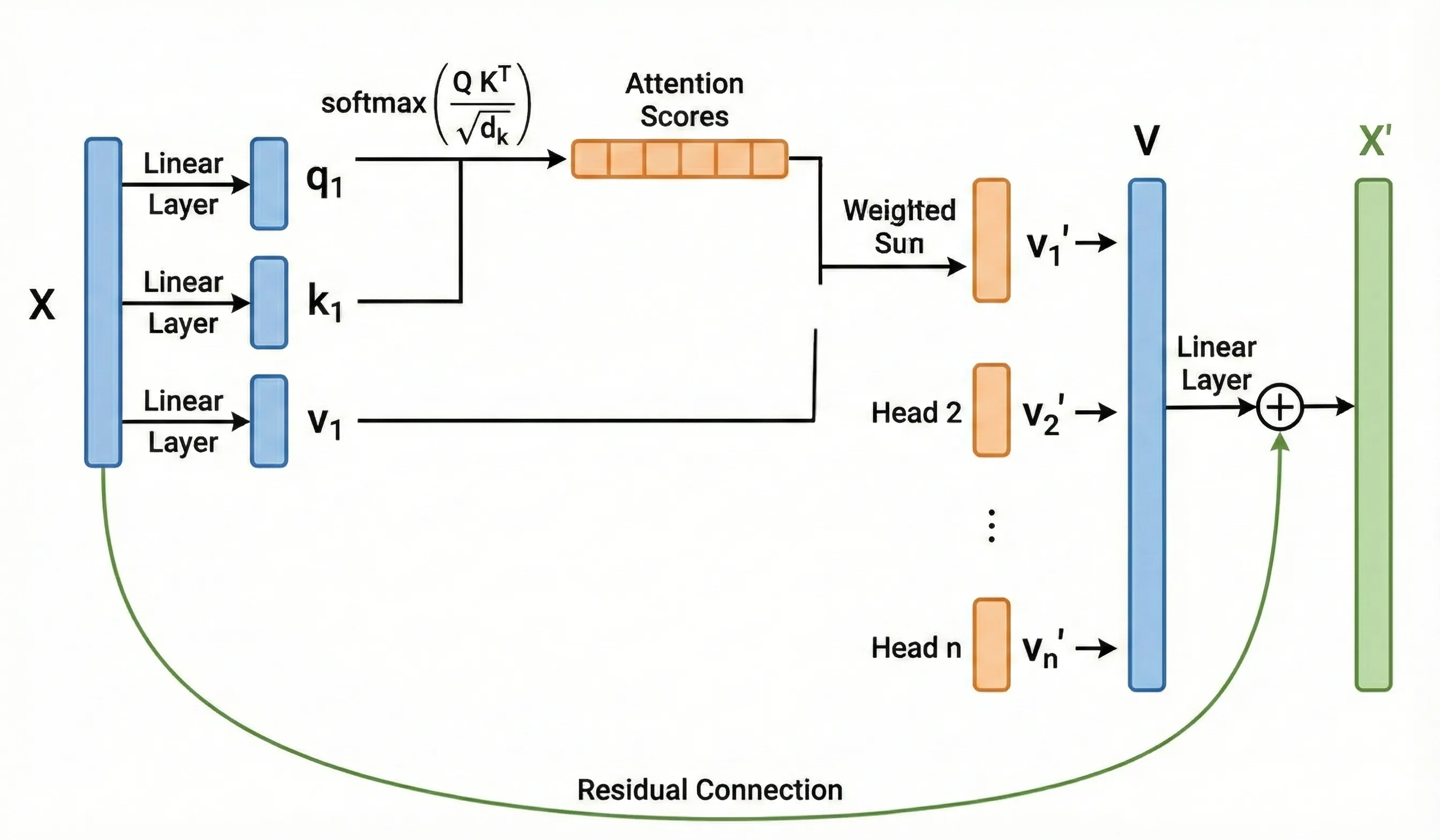
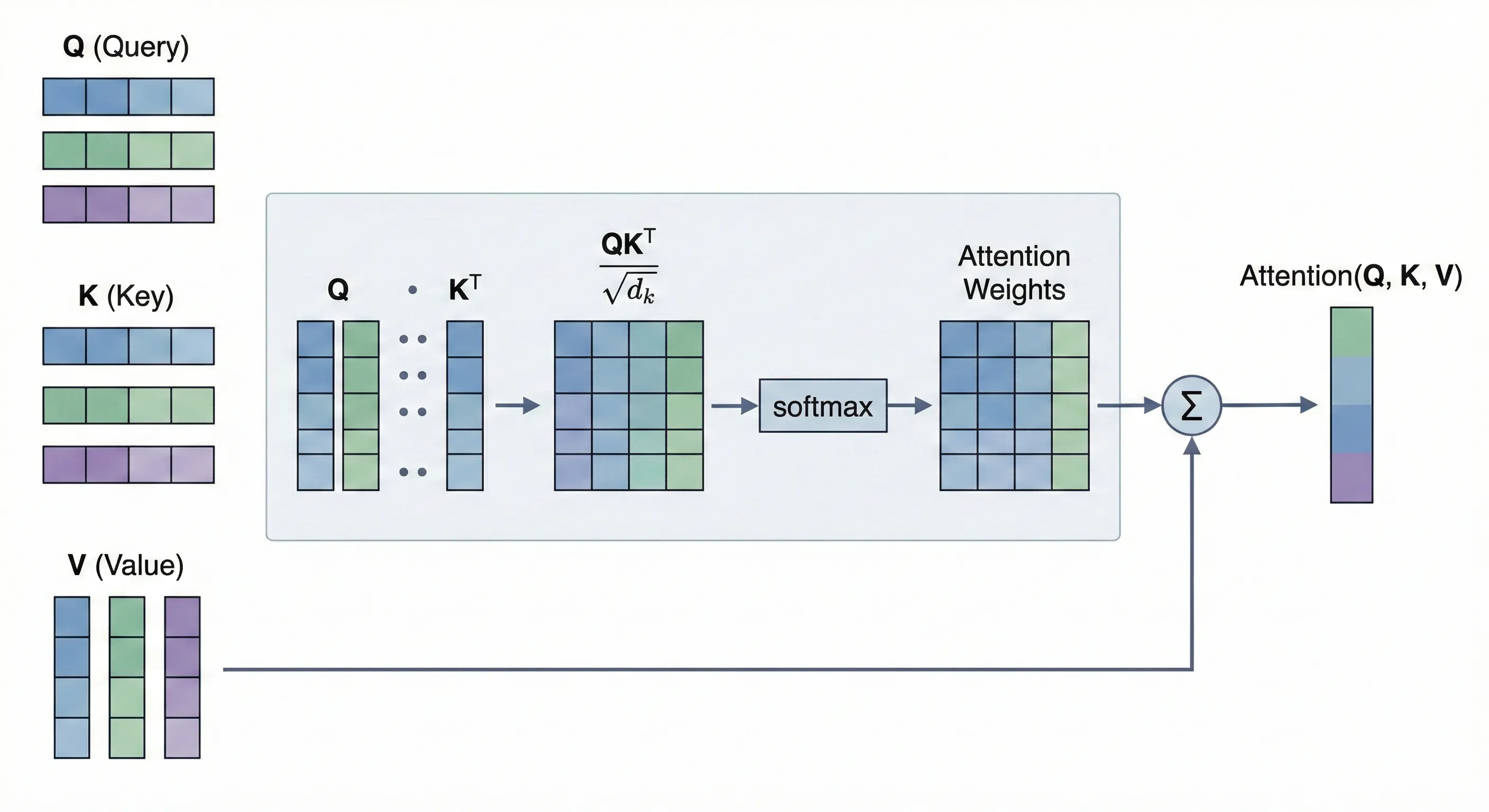 多头注意力:
多头注意力:
KV缓存与因果注意力机制
对于像GPT这样的decoder only架构,模型采用的是因果注意力,也就是当前的token只能看到它来自它前面的token的信息,现在会影响未来,但是未来不能影响过去,所以在不断的预测下一个词的时候当前的这个token在计算了QKV之后只会受到来自它前面的token的信息的更新,也就是说就算是后面token被预测出来之后当前token通过模型之后每一层计算出来的QKV也是一样的,所以我们就可以采用空间换时间的办法,直接把KV存起来,后面token通过模型的时候只需要计算这个token的QKV然后与前面token的KV缓存进行计算即可完成当前token的更新,这样就不用每一次都把整个序列一遍又一遍的喂到模型当中,每一次我只需要喂序列中的最后一个token,然后让这个token通过模型然后与前面序列的KV缓存进行交互计算即可,计算结束再把当前这个token的KV缓存起来。
那为什么不缓存Q呢?因为不需要,在推理阶段,我每一次只需要喂给模型一个token!!!也就是序列中的最后一个token,然后在做注意力计算更新的时候由这个token得到它的Q、K、V,然后用这个Q和进行交互计算就能更新这个token了。你看,整个过程并不需要来自前面的token的Q。
注意上面说的是在推理阶段,训练阶段则不同。同时还有一个重要条件就是这种因果注意力机制,每个token只能看到它前面的token,那么在推理的时候某个token经过模型然后得到的计算的结果就是固定的,不会因为后面更新的token而受到影响,所以我们可以把KV缓存起来避免每次都进行重复的计算,也是计算中经典的空间换时间的策略。
MHA、MQA、GQA
理解了KV缓存之后我们就可以看到为什么会出现各种注意力计算的变体了,因为KV缓存就是一堆矩阵,而且会随着序列的变长而不断增长,导致显存占用会越来越大,所以就出现了一系列的新方法来节省显存。其中一个就是对注意力的计算方式进行改变。
- MHA:多头注意力,最经典和标准的多头注意力,每一个头都有一套独立的
Wq、Wk、Wv权重矩阵 - MQA:多查询注意力,所有的Query头都共用同一组Key和Value
- GQA:分组查询注意力,将Query头分为G组,每一组的Query头共用一套Key和Value矩阵
MHA需要存储的KV缓存最多,GQA次之,MQA需要存储的KV缓存最少,当然性能肯定是MHA最好
这么看的话,是不是跟计算机的Cache映射的三种机制很相似呢,直接映射、组相联、全相联,最后用的最多也是组相联机制
MLP(FFN)
一般在transformer中用到的FFN就是一个MLP,也就是多层感知机,而这个感知机其实就是两个线性层加上一个激活函数的处理。
下面这张图在看了我上面提到的另外一篇博客之后再来看应该会有更好的理解
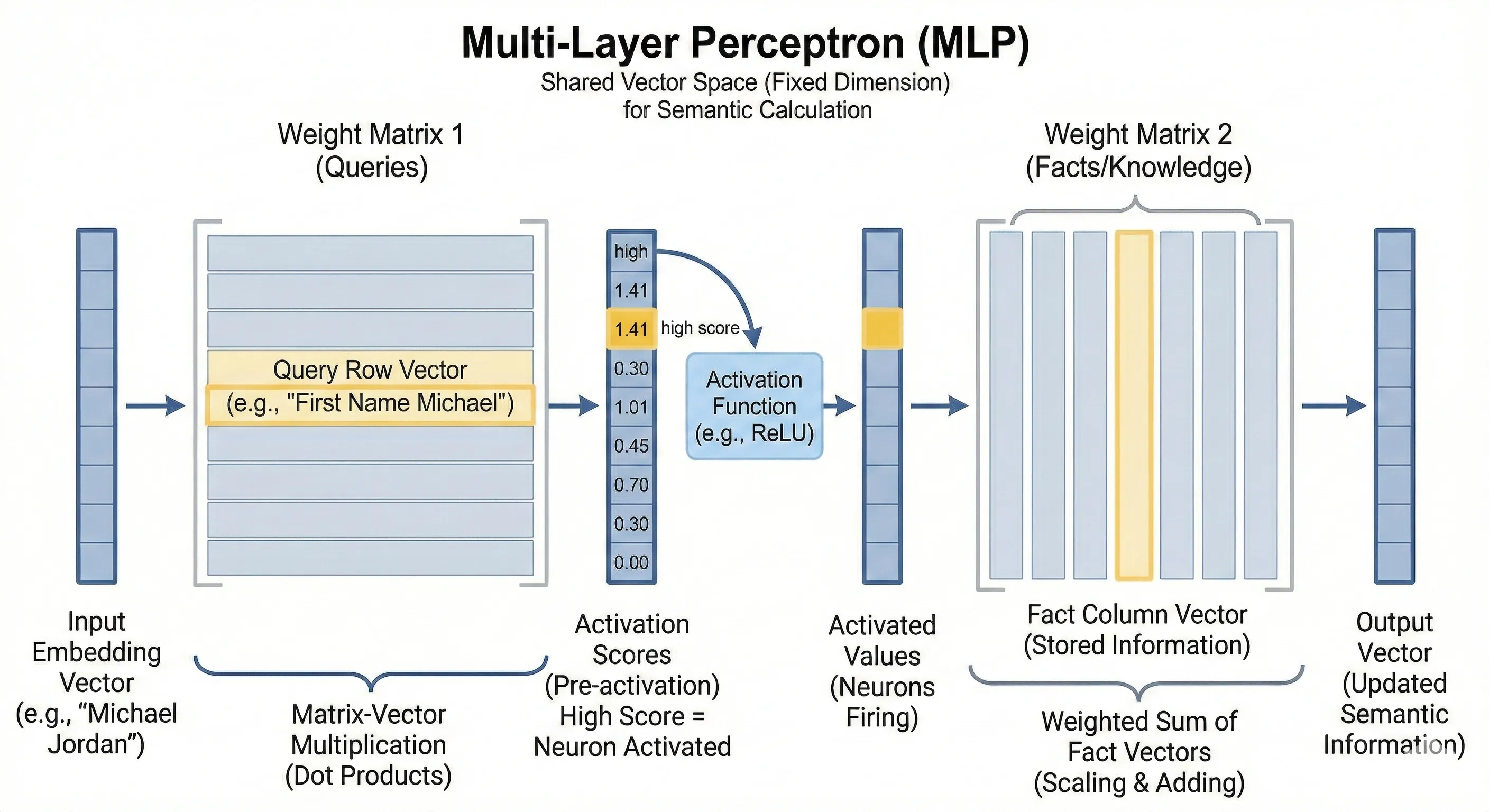
值得注意的是,Karpathy的代码中使用的激活函数操作是先经过ReLU之后再平方,为什么要这么做呢,我们先放一放
Value Embedding和门控
待补充
待补充内容:
- GPTconfig的滑动窗口注意力模式
- RMS Norm归一化
- RoPE(旋转位置编码)
- Value Embedding(值嵌入)
- SelfAttention和各种注意力的变体
- 激活函数与ReLU之后平方
- flash attention
- 词嵌入
- 优化器
- logits
- 损失函数
- 模型采样生成
- 线性层的直觉理解