Transformer From Scratch
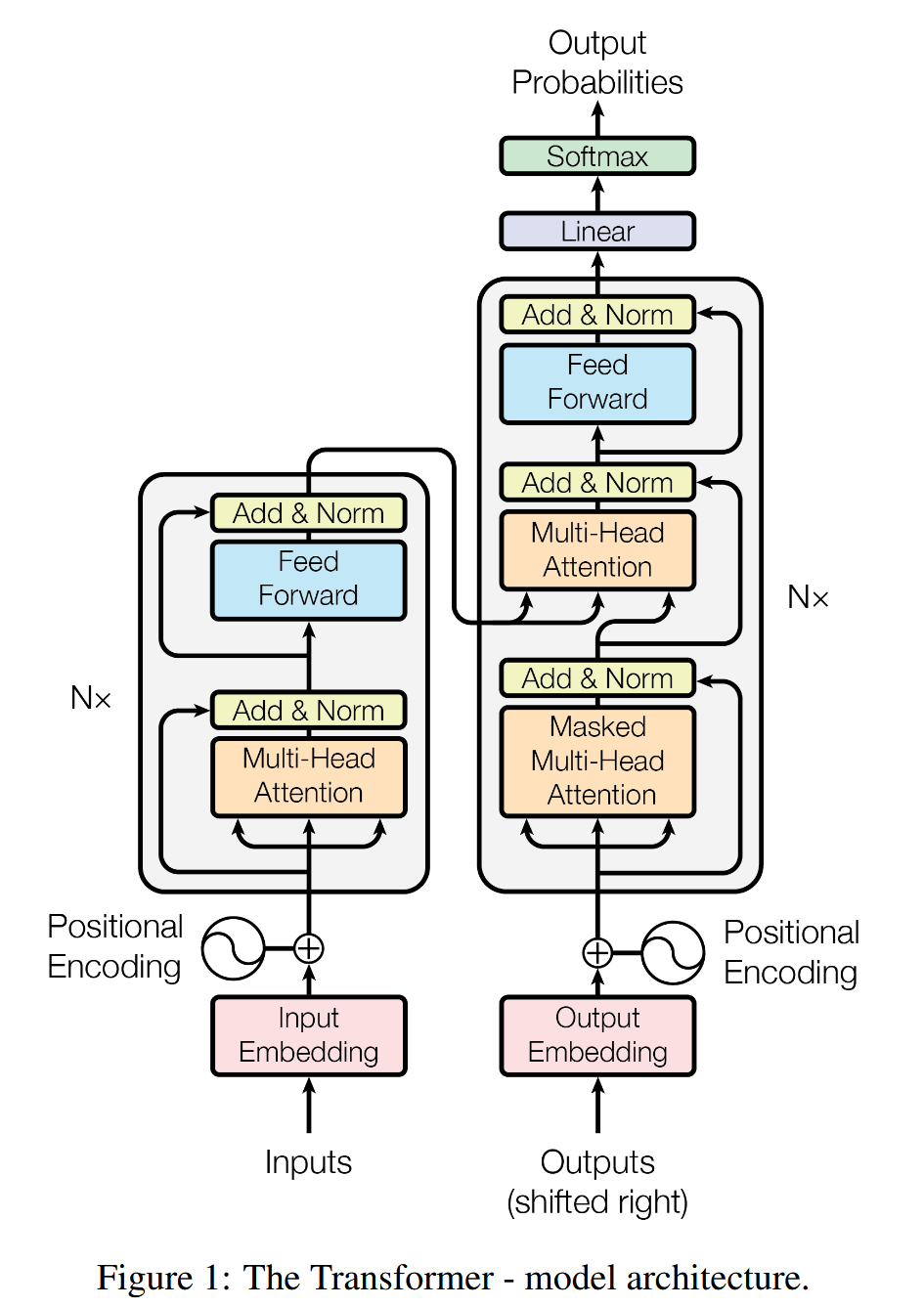
本文主要是对于transformer的每个部分的深入理解加上对于代码的部分关键信息进行解读和补充
关于代码的全部解释请见文章Transformer代码深入理解,建议两者结合阅读,先看本文的非折叠内容理解整个架构的设计以及详细解释,然后再看代码理解的文章同时遇到关键的部分再回到本文的折叠区(即“工程代码解读部分”)看相关代码的关键部分的解释
参考资料
整体架构
- Transformer
- Encoder * N
- Self-Attention
- Feed Forward Neural Network
- Decoder * N
- Self-Attention(Masked)
- Encoder-Decoder Attention(Cross-Attention)
- Feed Forward Neural Network
- Encoder * N
工程代码解读
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)src和src_mask的区别:input是长短不一的,所以需要为input加上pad,即把短句子用一个特殊的“占位符”(比如 [True, True, True, True, True, False, False, False]
tgt和tgt_mask在src掩码的基础上还加入了不让前面的token看到后面token的掩码,pad掩码部分和src一样
第一步—Tokenization & Embedding & Positional Encoding
分词
嵌入向量
就是用一个Embedding矩阵,将词表中的每个词和矩阵中的一个行向量联系起来
# 本质上是一个大的权重矩阵
embedding_matrix.shape = [vocab_size, d_model] # [30000, 512]
# 对于输入的词汇ID
word_id = 1234
word_vector = embedding_matrix[word_id] # 取出对应行作为词向量位置编码
如果只是有注意力和全连接层,一段序列的位置关系就会被忽略,所以需要引入位置编码 所谓的位置编码就是给embedding之后的向量加上了一个相同维度的代表这token位置信息的向量(遵循一定的模式),注意是两个向量相加,不是直接拼接在原本的向量后面,虽然应该也可以,但是那样会增加向量的维度导致后面需要的参数量也更多。
遵循什么模式呢?
位置编码会有不同的方式,通过不同的函数生成
第二步—Encoder
过程:整个架构就是完成一个input序列到一个putput序列的任务,而encoder负责的就是input的部分。编码器会接受一个向量列表作为输入(最开始是嵌入向量和位置向量的和),然后经过注意力层和前馈层之后传递到下一个encoder,经过多个encoder最后得到了一个向量列表会用于decoder的cross-attention层
工程代码解读
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)这里与原论文采用的有一点略微的差别,是更现代的方式,原论文中是Post-LN结构,也就是先经过子层然后再残差连接与层归一化,而这里则用的是Pre-LN结构,也就是先进行层归一化,再通过子层,然后进行残差连接,然后在通过了N个decoder层之后最后再来一次层归一化,例如6层的结构也就是进行了13次层归一化操作,而原论文中则只会进行12次层归一化操作。这样做的原因是在后续的研究和实践中,大家发现将层归一化放在前面(即 Pre-LN)会让训练过程更稳定,尤其是在模型层数很深的时候。很多现代的 Transformer 实现(比如 GPT-2/3 和 BERT 的一些变体)都采用了这种结构。
整个Encoder是6个EncoderLayer组成,每个EncoderLayer包含两个SublayerConnection,第一个是经过先层归一化然后经过注意力层然后进行dropout正则化再残差连接,第二是经过先层归一化然后经过FFN层然后进行dropout正则化再残差连接
注意力机制
自注意力机制就是让每个单独的token学到语境信息并更新,即让每个token向量变成一个在语境信息中更加准确的向量,从而将每个token转化为该token在语境中的高维精确的表达。
例如:”The animal didn't cross the street because it was too tired”
比如该句子中的it指代的是the animal,但是一个简单的it的嵌入向量只能表达最基本的代词含义,现在需要让这个it“注意到”animal,从而将这两个词联系起来,即是计算注意力分数然后根据animal的注意力分数较高,会让之后由animal得到的V向量的权重较大,使得animal对it的更新效果更加显著。当然,一个token对自身的注意力权重通常都比较显著,以确保其核心身份信息不会丢失。但最高的注意力权重会动态地分配给当前上下文中最重要的token(s),这其中可能包括它自己,也可能包括其他的token。例如对于 it 来说,animal 的上下文信息可能比 it 本身的(作为代词的)信息更重要。在这种情况下,模型可能会学到给 animal 分配比 it 自身更高的注意力权重。
- 自注意力机制通过一个加权求和过程,让每个token的向量表示融合来自句子中其他token(尤其是最相关的token)的上下文信息。在这个过程中,通过自身的注意力权重和至关重要的残差连接(为什么要引入残差连接),它又能确保token不会“忘记”自己是谁,从而实现对原始信息的保留和对上下文信息的精确更新。
- 自注意力机制的核心任务,就是计算出那个需要被加到原始向量上的“更新向量”或“残差向量”,然后与原始向量相加就得到了最后更新的向量
- 具体过程
-
第一步:将原始向量与三个矩阵Wq、Wk、Wv分别相乘得到Q向量、K向量、V向量,即一层注意力的参数就是Wq、Wk、Wv三个矩阵
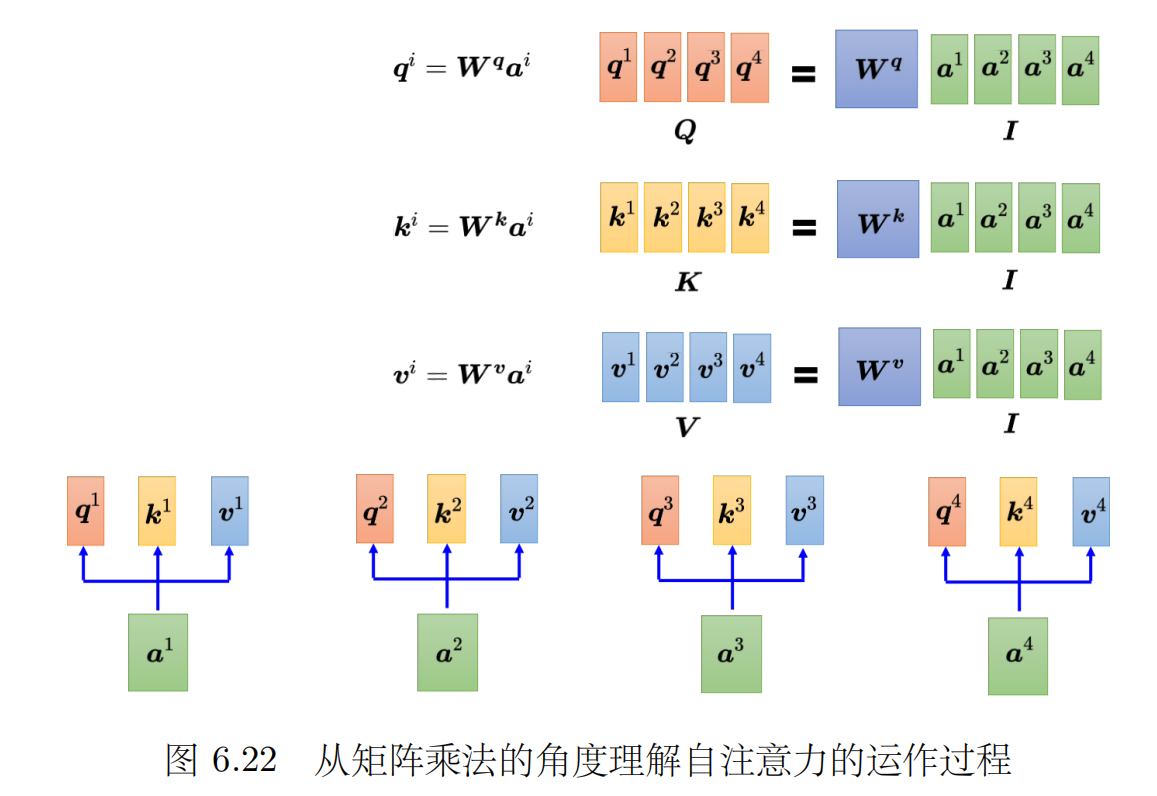
-
第二步:然后得到了三个矩阵Q、K、V,再让Q矩阵和K矩阵相乘得到每个向量与其他每个向量的注意力分数,K矩阵需要转置,就得到了向量的点积矩阵(注意力分数矩阵),注意这里注意力分数还要进行除以根号下dk(向量的维度)(防止产生过大的注意力分数和梯度消失问题,让模型无法学习多样化的信息,即最后的softmax结果几乎是一个one-shot向量)和一个softmax操作(让权重和为1,且都是非负数,这样的权重可以被理解为一个概率分布,它告诉我们应该将100%的“注意力”如何分配给序列中的所有token)
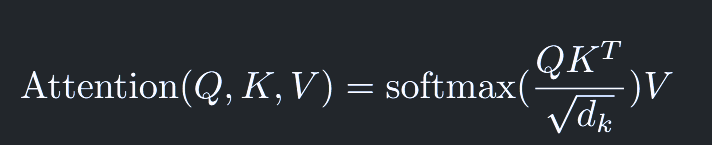

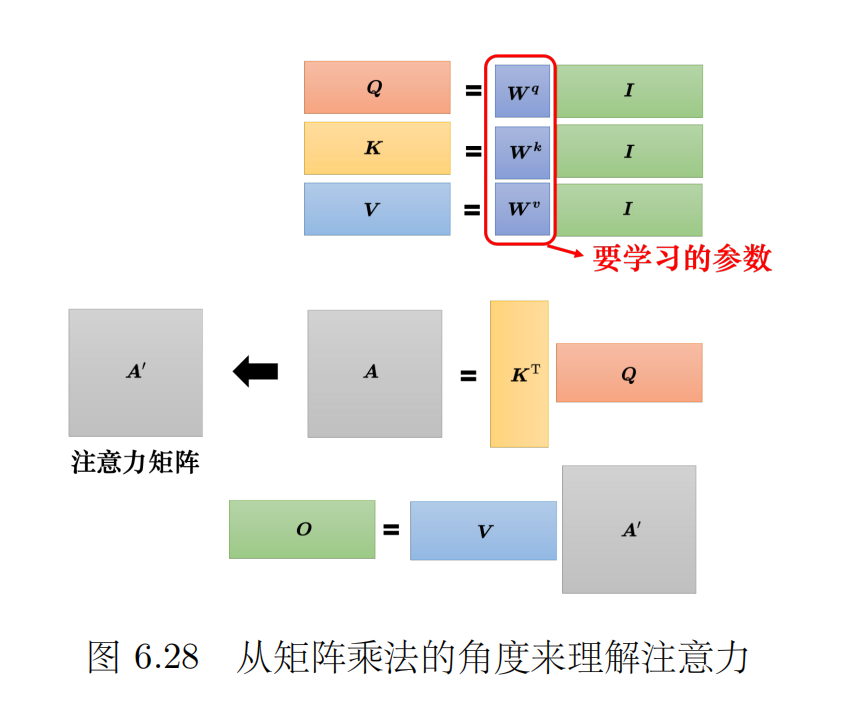
-
梯度消失的原因,当产生的数值特别大的时候,变化几乎不会导致结果的变化,也就是梯度为0,模型就会认为不需要再继续训练了

-
-
第三步:然后再根据注意力分数对V向量进行加权求和
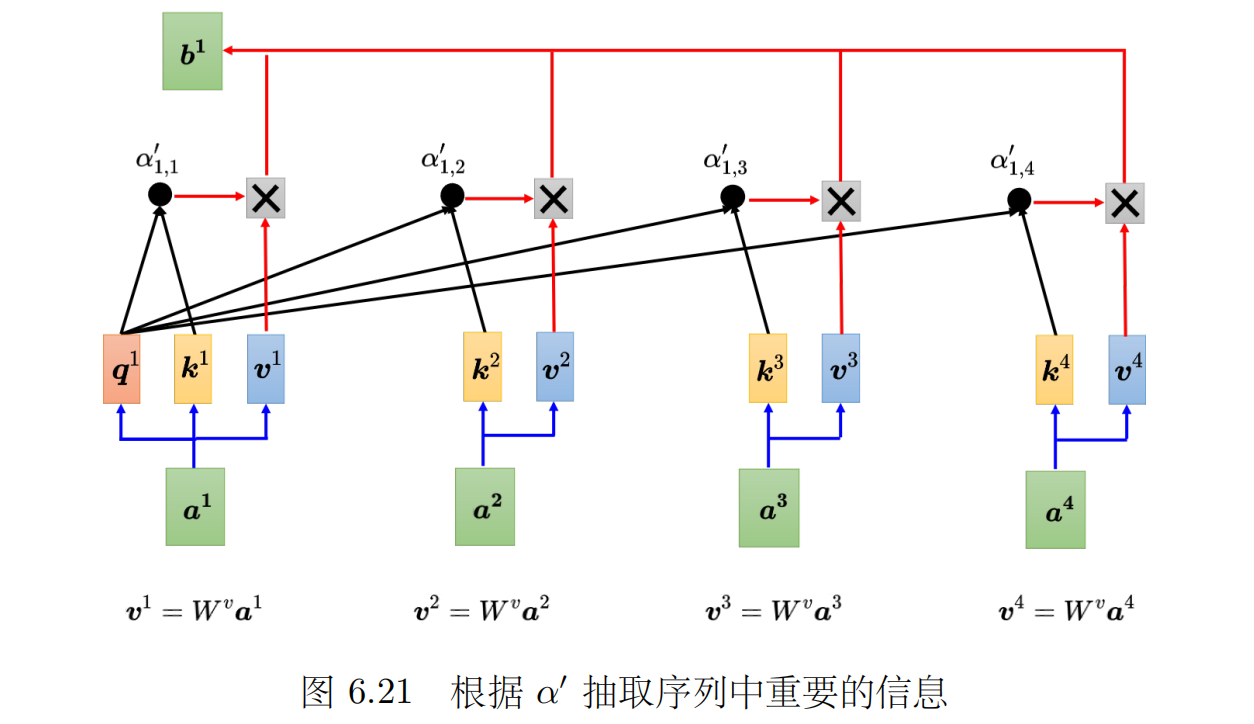
-
- 论文中所用的实际上是多头注意力来计算,也就是算出来的q、k、v向量跟原本的向量不是同一个维度,例如原向量是512维的,现在算出来的q、k、v都是64维度的
- 在实际的计算过程中用到的是矩阵计算,如图所示:
- 算Q、K、V矩阵:例如2个512维的向量,就是一个2 * 512的矩阵,然后乘以一个512 * 64的矩阵得到了两个64维的矩阵
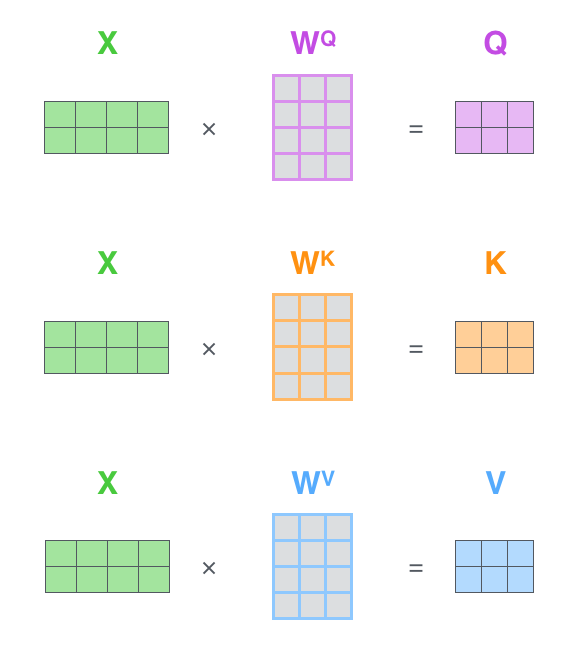
- 算注意力矩阵:Q为2 * 64的矩阵,乘以K的转置,也就是64 * 2的矩阵,也就得到一个2 * 2的注意力分数矩阵,这样算出来就是例如[1][1]的数值就是第一个向量对第一个向量的注意力,[1][2]就是第一个向量对第二个向量的注意力。然后除以根号下dk(key向量的维度),然后再做softmax,显然这里的softmax的计算就是对注意力矩阵的每个行向量进行操作,即每个行向量是作为一组来操作的
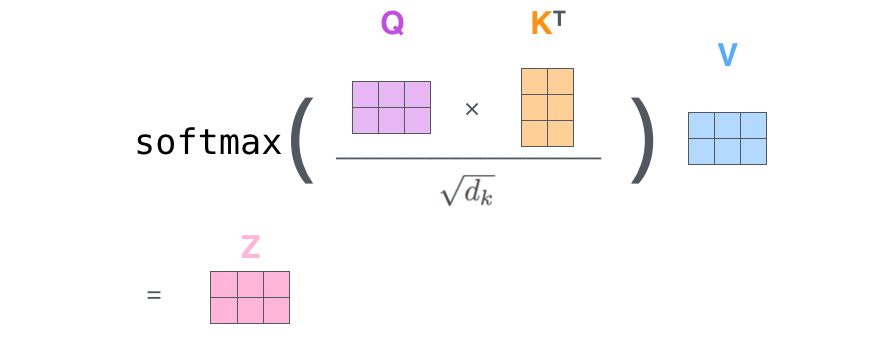
- 算Q、K、V矩阵:例如2个512维的向量,就是一个2 * 512的矩阵,然后乘以一个512 * 64的矩阵得到了两个64维的矩阵
多头注意力机制
过程
所谓的多头注意力就是原本是将原向量乘以三个矩阵:Wq、Wk、Wv转(线性变换)成维度相同的向量然后就可以一次性完成一次的注意力层,然后多头注意力就是变成了将原向量线性变换为了低维度的3个向量,例如原向量是512维的,现在得到的q、k、v都是64维度的,然后就会有8组Wq、Wk、Wv矩阵完整8次转化,每一组最终都会得到一个包含64维度向量组成的矩阵n * 64,然后把8组的矩阵拼接起来就是一个包含512维度向量的矩阵n * 512,注意这样直接拼接起来并不好,因为信息相当于是割裂的,就需要再乘以一个512 * 512的矩阵相当于把8个64维度的信息片段的信息进行整合,重新变成一个完整的向量。
![]()
为什么这样做
为什么不直接将Q、K、V变换为512维度的呢?这样不是更加方便吗,分成8次的注意力计算有什么好处?最后还要再乘以一个矩阵来整合信息,还增加了参数量和计算量
- “It expands the model’s ability to focus on different positions.”
- 每个头关注的是不同的信息,然后这样就能学到更加丰富的内容,注意力是加权平均的操作:每个位置是看“所有其他位置”的加权和,所以这种“平均”会有可能模糊具体细节,尤其是当多个位置有相似内容时。多头注意力用多个“注意力头”同时从不同角度学习注意力权重,可以一定程度上保留更多细粒度信息。Transformer 能快速捕捉远程依赖,但注意力有平均化的副作用,作者通过多头注意力来缓解这个问题。
- “It gives the attention layer multiple ‘representation subspaces’”
这么看的话,transformer就跟CNN很相似了,每个注意力头关注的是不同的地方,然后通过乘以一个大的变换矩阵就形成更大的特征提取与融合
前馈神经网络
这一部分受到了3Blue1Brown视频(bilibili)(youtube)的指导,讲解的非常精彩,如果你也感兴趣,请务必去看一看,同时该系列视频的其他视频也值得一看
所谓前馈神经网络其实就是一个MLP(多层感知机),即让向量先通过一个线性层然后使用激活函数再经过线性层,至于具体的线性层层数这些是模型架构设计的一部分,每个线性层其实就是在做一次线性变换,所谓加权求和,两个神经元之间的连线上的权重其实就是这个线性变换对应矩阵的某个位置的一个值。我们把需要变换的向量看成一个列向量,第一个线性层就是让这个列向量左边乘以一个变换矩阵,变换的结果就是矩阵的每一行是一个行向量跟这个列向量做点积(矩阵看成行向量是因为行向量才是跟embedding处在同样的向量空间中也就是可以进行计算的),例如原本列向量代表的是Michel Jordan,矩阵的某个行向量代表First Name Michael,那么我们可以理解为原列向量蕴含了这个行向量的编码信息,也就是说列向量在行向量上的投影几乎就是行向量本身,那么可以简单理解维这两个向量做点积的结果就是1,也就是所谓的神经元被激活了。然后经过激活函数之后,我们来到了第二个线性层,这个线性层我们更好的方式是将权重矩阵看作是列向量(因为第二个层的列向量才是跟embedding处在同样的向量空间中,即维度是一样的),矩阵乘以列向量就是神经元对应的激活值乘以其对应位置的列向量然后求和,这里也就是被激活了的神经元在权重矩阵中对应的列向量的编码会被加到最后的结果中
由此可以见到,所谓的权重也可以是看成了储存在模型中的向量信息,每个向量也是有他所代表的信息,也就是模型储存了事实,第一个线性层的权重矩阵的每一行都看成是一个“查询”向量,查询向量与原向量做点积就可以得到这两个向量的关系,如果结果很大就是算出来的结果对应的神经元会被激活,第二个权重矩阵的每一列看成是一个事实向量,其对应的神经元被激活,这个向量就会被加到最后的结果中
第一个线性层的矩阵看成是行向量的组合,第二个线性层看成是列向量的组合,因为他们才都是和原本的embedding处在同一个向量空间中,我们将所有的语义信息都在这个预设好维度(即每个token对应embedding向量的维度)的向量空间中进行存储和计算,我们几乎所有的工作都是在使用这些存储在这个特定空间的向量进行计算,如算点积(计算相似度)、相加减(更新语义)等等等等
不过,以上只是一种简化的理解方式,实际上单个神经元对应的向量可能并不是代表想Michael Jordan这样的简单事实,而在科学上还提出过有关“叠加”态的说法
在N维的向量空间中最多只能有N个互相垂直的向量,但是,一旦我们将要求降低一点,让向量之间的夹角在89-91度之间,根据Johnson-Lindenstrauss Lemma,满足这样条件的向量的数量会随着维数的增大而呈指数级的增长,也就是向量空间所能表征的“概念”数量会指数级的增加,或许这也就能解释为什么模型的参数规模到了一定的水平之后会出现涌现的能力
残差连接
残差连接就是让经过了注意力层或者FFN生成的向量和原本的没有经过网络的向量直接相加之后再进行层归一化处理
理论上来说,更深的网络一定不会比浅的网络的性能差,因为深的网络只需要让后面的层变成恒等变换层就会与浅层网络一样,但是实践上发现要让网络拟合出一个恒等变换是很困难的,而网络拟合一个0函数就很简单,即让F(x)=0,因为只需要让权重全部变成0就可以了。于是就引入了残差连接,即让网络学习的是输入与输出之间的差函数,这样,一个恒等变换网络就等于一个残差为0的网络加上残差连接即可。而注意力层就是学习的残差函数
残差连接改变了自注意力层的学习目标
- 没有残差连接时:自注意力层需要学习一个完整的变换函数
H(x),直接输出最终的目标向量。这很难。 - 有残差连接时:自注意力层只需要学习残差(Residual)
F(x) = H(x) - x。也就是说,它只需要学习“需要做的改变量”或者说“更新量”。
如果模型发现不需要做任何改变,它只需要让自注意力层输出一个零向量就行了,这比学习一个恒等变换(输入什么输出什么)要容易得多。

层归一化
层归一化是一种技术,它针对单个样本的所有特征(即单个向量内部),通过调整其数值的分布,使其变得“整齐”(通常是均值为0,方差为1),从而让神经网络的训练过程更快速、更稳定
在 Transformer 的 Encoder 或 Decoder 层中,数据是以 [批次大小, 序列长度, 嵌入维度] 的形式流动的。层归一化(LN)作用在最后一个维度上。也就是说,它会独立地处理序列中的每一个词元(Token),对这个词元的整个 512 维的嵌入向量进行归一化操作
第三步—Decoder
Decoder负责的是Output序列,整个过程就是不断的将decoder的输出作为新的输入给decoder然后让decoder不断生成下一个token直到生成一个特殊的结束token
重要:所谓的生成下一个token就是每一个token经过decoder之后就会生成一个代表概率的向量,向量的某个位置的值代表着当前token对于下一个token在这个index下(例如向量的第5维度代表着词表中的某个特定的词)对应的词的概率,也就是说每个token经过decoder之后都会生成一个预测向量,只不过在推理阶段我们只需要取最后一个token的预测向量来生成下一个词而已,而在推理的时候则是会用到所有token生成的预测向量,看看这个预测向量代表的词和实际的标签是否相符合罢了
在推理的时候,Decoder处理的第一个Token向量来自于一个人为添加的、代表“句子开始”的特殊标记,通常被称为
在训练时,Transformer用了一个“障眼法”(Mask),让GPU可以同时为序列中的每一个位置都执行一次“一次只预测一个词”的任务,从而把原本需要N步的串行计算,变成了一步完成的并行计算,极大地加速了训练过程。这个设计正是Transformer能够处理长序列并在大规模数据上成功训练的关键之一
工程代码解读
Decoder也是由6个DecoderLayer组成,每个DecoderLayer则是由三个SubLayerConnection做成,第一个是先经过层归一化然后再经过注意力层(这里需要用到特别的掩码即既有对pad的掩码,也有对未来token的掩码)然后再dropout正则化然后再残差连接,第二个是先经过层归一化然后再经过cross-attention层(即K、V来自encoder,Q来自上一个DecoderLayer的输出)然后dropout正则化然后再残差连接,第三个是先经过层归一化然后再经过FFN然后dropout正则化然后残差连接
掩码注意力
掩码的目的主要是用在模型训练的时候。
在训练时,我们已经拥有了完整的源句子和对应的目标句子,输入的准备如图
 也就是说,在训练的时候,输入了sos,然后让模型根据sos和原始的输入来预测下一个词也就是Wie,即前向传播一次,然后再反向传播进行梯度下降来修改参数让模型预测的更准确,然后输入sos、Wie让模型预测geht,以此类推,这样sos和eos的加入刚好让标签和实际输入错开了,从而保证了自回归生成。但是!!!注意了,实际训练过程,加上了sos的序列会被全部放进encoder中
也就是说,在训练的时候,输入了sos,然后让模型根据sos和原始的输入来预测下一个词也就是Wie,即前向传播一次,然后再反向传播进行梯度下降来修改参数让模型预测的更准确,然后输入sos、Wie让模型预测geht,以此类推,这样sos和eos的加入刚好让标签和实际输入错开了,从而保证了自回归生成。但是!!!注意了,实际训练过程,加上了sos的序列会被全部放进encoder中
为什么?不是一次只能预测一个词吗(对也不对)
实际上decoder是能够一次性预测所有的词的,只不过是推理的时候只用到了最后一个token的预测,而在训练的时候是会用到所有的token的预测的,也就是根据预测来反向传播调整参数
那么这个时候就需要引入掩码了,因为预测的时候不能让当前token看到他后面的token(也就是实际的“答案”)
掩码操作
例如,当计算第三个位置(“geht”)的输出时,自注意力机制会计算它与序列中所有其他词的“注意力分数”。Mask矩阵会强行将它与自己及之后位置(“geht”, “es”)的注意力分数设置为一个极大的负数(比如 -1e9)。也就是给计算出来的注意力分数矩阵加上了一个特别的矩阵,矩阵的右上方全是负无穷,左下角全是0,也就是让原本注意力分数矩阵的右上角全部变成负无穷(右上角的数值代表的是前面token对于他后面的token的注意力分数)
这样一来,在经过Softmax函数之后,这些位置的注意力权重就变成了0,也就不会让前面的token看到后面的答案了(后续在加权求和的时候就不会加上来自后面的token生成的V向量)
Cross-Attention(Encoder-Decoder Attention)
这个是一个特殊的注意力层,与self attention唯一的不同就是K、V矩阵是来自encoder最后一次输出的向量生成的K和V,而Q则是由经过了掩码注意力层之后生成的向量生成的。在cross-attention模块中,来自答案的Q和来自encoder的K算出了注意力分数矩阵,这个注意力分数矩阵然后会和来自encoder的V矩阵相乘得到新的一组向量再和原向量进行了残差连接并进行了层归一化处理
这样做的原因就是让输出作为查询,而来自encoder的信息就是作为一份已经理解好的超级“文档”,让来自decoder的序列来注意到来自encoder的信息,从而实现信息的融合
信息融合本身不是目的,它是一种手段。其最终目的,是让模型在预测下一个词时,能够做出一个更明智、更准确、几乎是唯一正确的选择。如果说Cross-Attention是“博览群书”(吸收信息),那么FFN就是“消化理解”(深度思考)。它会将收集到的信息进行提炼、组合和筛选,识别出更复杂的模式,最终输出一个更加精炼、意图更加明确的向量。“正因为融合了信息,这个向量才从一个‘充满可能性的模糊状态’,变成了一个‘指向正确答案的确定状态’。”
最后—Linear & Softmax
经过decoder最后模型会生成一堆向量,但是这个向量还不是最终的预测向量,这个向量还要经过一个线性层生成一个巨大的(维度跟词表中词的数量一样)每个维度包含其对应词的预测分数的向量,然后这个分数向量再经过softmax生成概率向量就完成了
Linear
线性层就是一个简单的全连接神经网络将解码器产生的向量线性变换到了一个巨大的向量
Softmax
softmax没啥好说的,就是一个计算过程,取一组值然后生成一个概率分布,分数越大概率就越高,所有值对概率的和为1
Something Special
损失函数
在训练的时候,我们假设我们的输出词汇表只包含六个单词(“a”、“am”、“i”、“thanks”、“student”和 “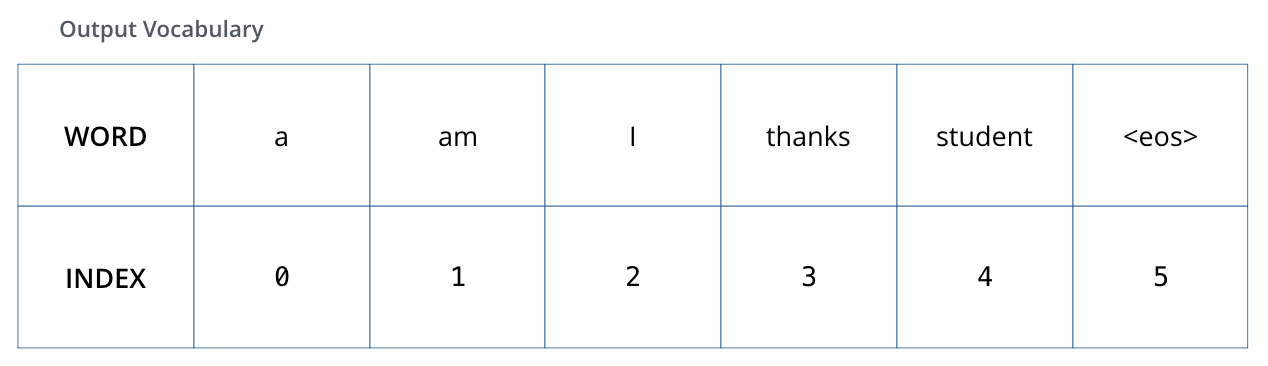 即每个词对应了一个index值,然后我们还有one-shot编码
即每个词对应了一个index值,然后我们还有one-shot编码
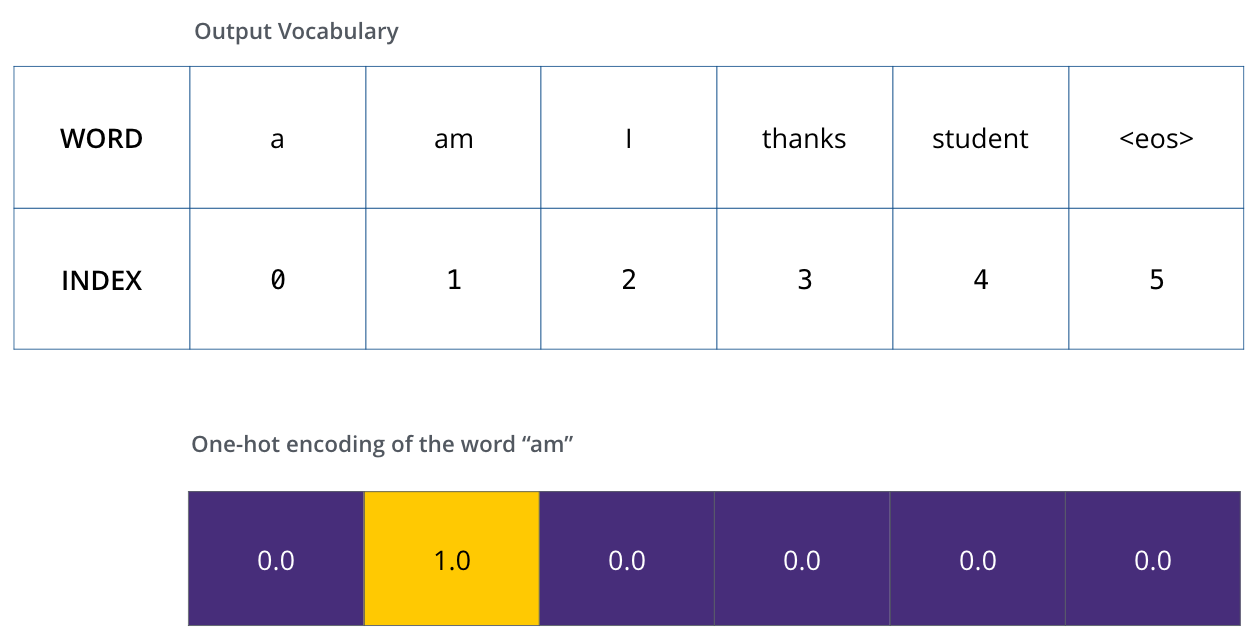 就是为每个词编码为当前第index维的值为1,其余都是0的一个向量,然后我们不是经过decoder之后就会有一个跟词表维度一样的预测向量吗,如果模型预测的准确,那么这个预测向量就应该是当前词对应的one-shot向量(这个维度的概率为1,其他维度的概率为0嘛)
就是为每个词编码为当前第index维的值为1,其余都是0的一个向量,然后我们不是经过decoder之后就会有一个跟词表维度一样的预测向量吗,如果模型预测的准确,那么这个预测向量就应该是当前词对应的one-shot向量(这个维度的概率为1,其他维度的概率为0嘛)
这样,我们就可以计算损失了,即预测向量与one-shot向量的交叉熵或者是KL散度等等
并行
在进行注意力计算的时候,某个token的计算会依赖于其他token,但在实际的计算过程中是进行矩阵乘法,所以仍然是并行计算,不过在前馈层是没有token间的依赖关系的,可以单个token直接进行计算,所以可以并行计算(也是矩阵乘法)